Example#
This page illustrates the main code sections on how to access the selected dataset from a Jupyter notebook. The information presented here assumes that you already have performed the following actions:
logged in to SciCat
retrieved your access token, using the SciCat frontend
selected the dataset(s)
copied its pid
Please review the SciCat page if you need more details on where to find this info.
We use the Scitacean Python library to interact with SciCat from Python.
In addition to the code snippets contained in this page, we have prepared three jupyter notebooks ready for use which you can adapt to your needs in order to download and upload dataset(s).
scitacean upload dataset
scitacean download dataset
scicat widget
Use case#
Let’s say that you have performed a search in the SciCat frontend and you have identified a specific dataset that you would like to use for your data analysis.
You need two pieces of information: the dataset pid and the access token.
In this example, we use the following:
(You need to use your own token, this one won’t work for you.)
dataset_pid = "20.500.12269/761fd17f-e0a8-4bd4-9e70-67ff8647b3f4"
access_token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJfaWQiOiI2MzliMmE1MWI0MTU0OWY1M2RmOWVjMzYiLCJyZWFsbSI6ImxvY2FsaG9zdCIsInVzZXJuYW1lIjoiaW5nZXN0b3IiLCJlbWFpbCI6InNjaWNhdGluZ2VzdG9yQHlvdXIuc2l0ZSIsImVtYWlsVmVyaWZpZWQiOnRydWUsImF1dGhTdHJhdGVneSI6ImxvY2FsIiwiaWQiOiI2MzliMmE1MWI0MTU0OWY1M2RmOWVjMzYiLCJpYXQiOjE2OTIwODc0ODUsImV4cCI6MTY5MjA5MTA4NX0.Phca4UF7WKY367-10Whgwd5jaFjiPku6WsgiPeDh_-o"
You also need the address of the SciCat instance.
In this workshop, we use the “staging” instance which is useful for testing and experimenting:
scicat_instance = "https://staging.scicat.ess.eu/api/v3"
First of all, you need to import the scitacean library
from scitacean import Client
from scitacean.transfer.sftp import SFTPFileTransfer
Instantiate the client
client = Client.from_token(
url=scicat_instance,
token=token,
file_transfer=SFTPFileTransfer(
host="sftpserver2.esss.dk"
))
than request and retrieve the dataset selected
dataset = client.get_dataset(dataset_pid)
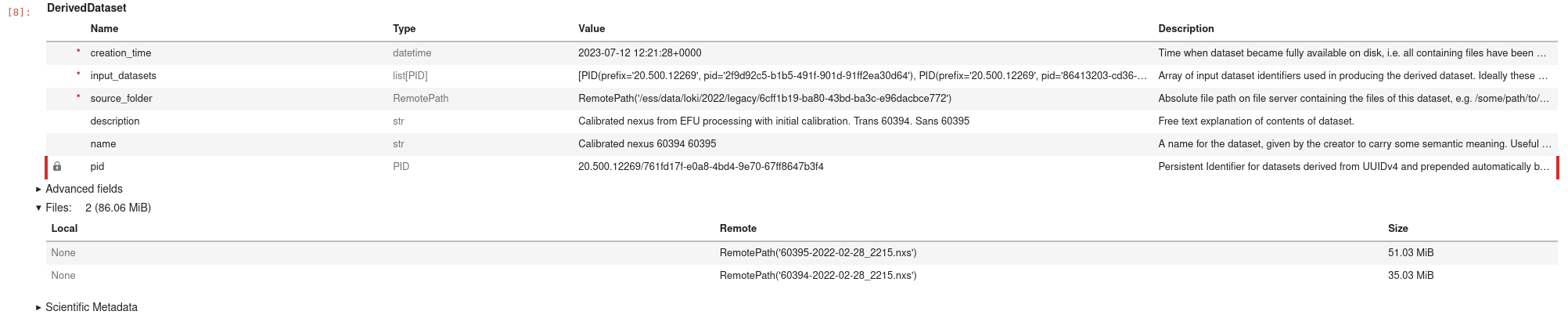
You can view the dataset information and metadata
dataset
This command presents the following view which shows the main information about the dataset.

You can expand the collapsed sections to view the metadata

or the file associated with the dataset.
Once you have verified that the dataset is the correct one, you can download the data files
dset = client.download_files(dset, target="../data", select="60395-2022-02-28_2215.nxs")
dset
If we check the files section of the dataset, we can see that the file has been downloaded:
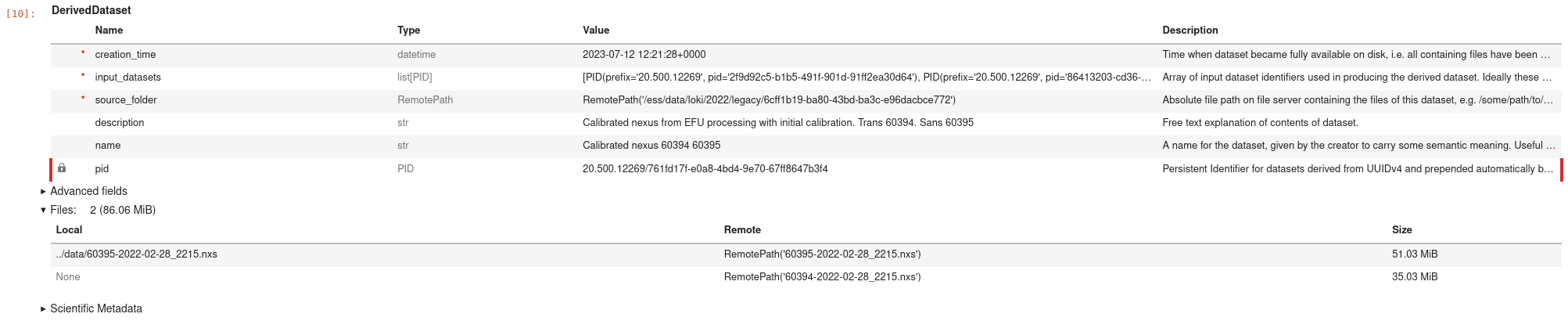
The current status of the dataset indicates that the first file is available locally with path
..\data\60395-2022-02-28_2215.nxs
Please note the relative path.